Server
Architecture Design
We are using a very typical web server design architecture for our server (similar to spring boot's architecture).
See Spring Boot - Architecture - GeeksforGeeks for a detailed tutorial on this topic.
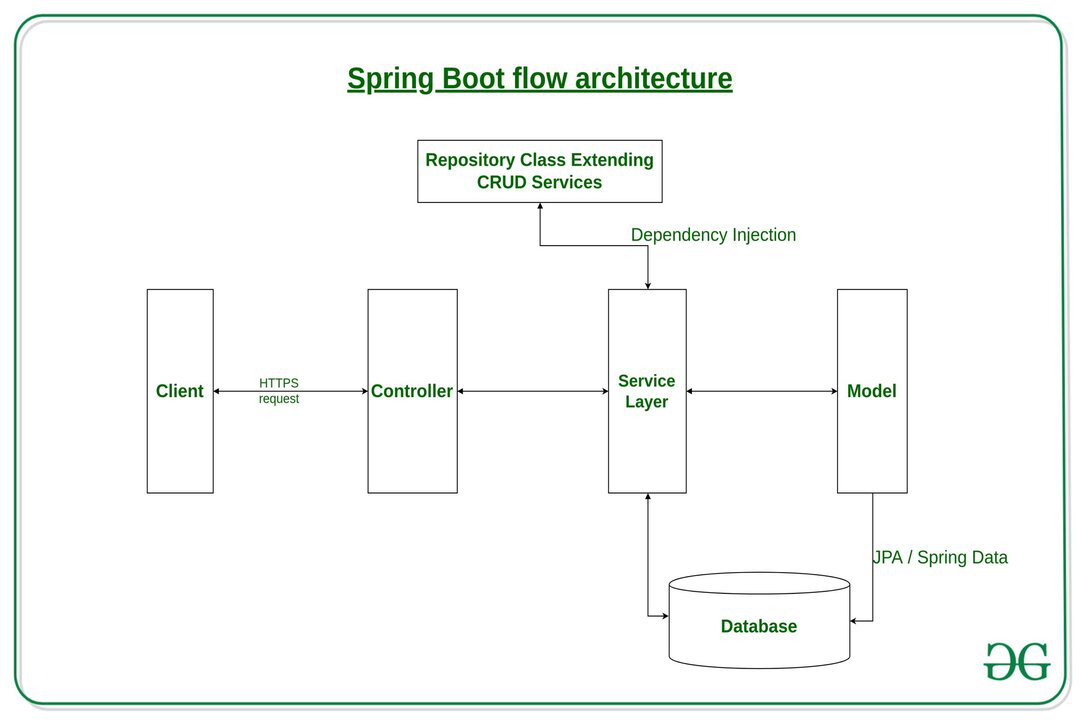
Since we are using GraphQL for frontend-backend communication, GraphQL resolver will be equivalent to the controller in the standard architecture.
The resolver will be calling methods in different services (e.g. user service, record service).
The service layer will do all the work/business logic such as CRUD operations on persistent database and cache.
Discussion on Data Accessing
With a common interface, we can switch database under the hood without modifying much service code.
The logic between service and database is usually abstracted into DAO (data access object), which is an abstract interface for communicating with databases. Another concept related to database is repository. It also provides abstraction on data accessing, so what's the difference?
The repository pattern provides a higher level of abstraction compared to the DAO pattern. In the repository pattern, the application interacts with the data storage layer through a set of interfaces that provide a higher level of abstraction. The repository interface abstracts away the details of data storage and retrieval operations, providing a simplified and consistent interface to the application. The repository pattern also provides an additional layer of abstraction to implement business logic that may involve multiple data entities.
In our design, the task of DAO is with Prisma, an ORM library. Repository classes will call prisma to retrieve data.
Why do we need a repository layer?
- If we want to stop using Prisma one day, we don't need to change the high level business logic. Instead we just update which DAO to call in repository implementation
In our design, repository is implemented with service classes. We call both business logic service class and repository classes service, but the logic/code are implemented separately. We may consider renaming in the future if it's confusing. I will talke about this in Service Design.
Controller
As mentioned above, this will be the GraphQL resolver, it is like a main function, responsible for calling service methods, aggregating data and respond to client upon a request.
Here is an example of how it look like in our code
const resolver: gqlResolver.Resolvers = {
Mutation: {
addRecord: async (
_,
{ deviceId, profileId, type, value }: req.MutationAddRecordArgs,
ctx: IsAuthGraphQLContext
): Promise<req.AddRecordResponse> => {
return (
recordService
.addRecord(ctx.user.id, deviceId, profileId, type, Buffer.from(value))
.then((record) => {
const gqlRecord = prismaRecordToGQL(record);
pubsub.publish(SubscriptionTopic.NEW_RECORD, {
recordSync: gqlRecord,
sessionId: ctx.user.sessionId,
});
const msg = {
value: JSON.stringify({
value: gqlRecord.value,
type: gqlRecord.type,
profile: gqlRecord.profile,
createdAt: gqlRecord.createdAt,
}),
};
return {
success: true,
record: gqlRecord,
message: "Successfully Uploaded",
id: record.id,
};
})
.catch((err) => err)
);
},
},
};
This gql mutation is responsible for adding a new record to database using record service and calling pubsub.publish to publish the event to other connected devices so that data is in sync.
Service and Repository
See Service Design